The NameNode is the most critical piece of the system of an HDFS file system. The NameNode manages the entire HDFS file system metadata (i.e owners of files, file permission, no of blocks, block locations, size etc.) and maintained it in main memory. Clients first contact point is the NameNode for file metadata and then perform actual file I/O directly with the DataNodes. If something goes wrong with the NameNode, then whatever metadata was there in main memory would get lost permanently.
To overcome metadata lost problem, HDFS maintain snapshot of entire in memory file system into disk as fsimage file. The file is located in the directory pointed by the “dfs.name.dir” parameter (configuration file “hdfs-site.xml“) in NameNode.

But this fsimage file being used and get loaded into memory when NameNode gets started. It’s interesting to note that the NameNode never really uses these files on disk during runtime, except for when it starts. Because updating the potentially massive fsimage file every time a HDFS operation is done can be hard on the system. So, it creates problem as stated in Issue-1.
Issue-1: Lets say you have done so many changes like creating directories, files, putting the data to HDFS during runtime this information is directly loaded into the memory but what if NameNode goes down so whatever new meta information was there which is not updated the current fsimage file, it would get lost permanently because when ever your system would come up (restart) it would load the fsimage into memory since its the old fsimage it won’t have new changes.
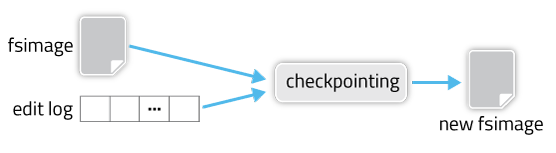
Solution-1: The edits/editlog file (also called transactions log stored in disk) stores all changes that occur into the file system metadatas in memory during runtime. For instance, adding/ deleting/ renaming/ moving a file in HDFS is traced in this file. The process that takes the last fsimage file and apply all changes which is found in editlog file and produce a new up to date fsimagefile, called checkpointing process. Checkpointing process only done at the time of NameNode server start up.
Here is an example of an HDFS metadata directory taken from a NameNode:

Now checkpointing process solve our UseCase-1 problem. Now it’s crucial for efficient NameNode recovery and fast restart, if the NameNode crashes, it can restore its state by first loading the last checkpointed fsimage file into memory then replaying all the operations (also called edits or transactions) in the edit log to catch up to the most recent state of the namesystem. But this checkpointing process is very resource expensive and take long time due to drastically increased editlog transactions volume. The NameNode itself doesn’t do checkpointing process, because it’s designed to answer application requests as quickly as possible. More importantly, considerable risk is involved in having this metadata update operation managed by a single master server. So, it creates problem as stated in Issue-2.
Issue-2: We had a situation in which the checkpoint operation did not occur for last 60 days (i.e. last NameNode server started 60 days back), and it took around 12hours for the checkpointing process to complete. So, NameNode busy replaying edit logs, and during this period the HDFS cluster is unavailable and does not respond to HDFS queries. By this way, restarting of NameNode server is going to take longer even if you are in hurry due to production environment urgency.
Solution-2: Secondary NameNode is solution for this issue. This is another machine having connectivity with NameNode. It periodically copies latestfsimage file (only first time) and editlog files from NameNode and and merges them together, into a new checkpointed fsimage file and moved back the newly created fsimage file to NameNode. This is an important process to prevent edits from getting huge and ensure that the NameNode server recovery and restart is faster. Secondary NameNode whole purpose is to have a checkpoint in HDFS. Remember, Secondary namenode is not backup node or HA(High Availability) Namenode. However it is notoriously inaccurate name in Hadoop system. It should be checkpoint Node.
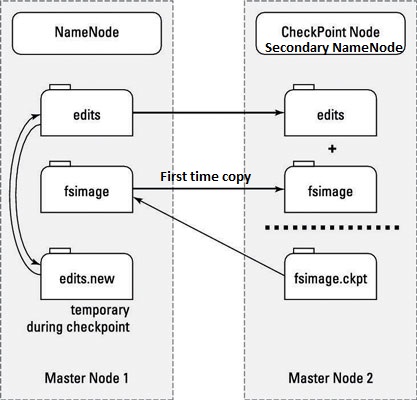
Issue-3: Now if NameNode goes down before checkpointing process, then all the operations which took place after last checkpoint will be lost.
Solution-3: So we need to consider Backup Node which maintains a real-time backup of the NameNode’s state and also providing checkpointing functionality. If we’re using the Backup Node, we can’t run the Checkpoint Node or Secondary NameNode. There’s no need to do so, because the checkpointing process is already being taken care of.
Issue-4: Now everything goes fine until NameNode is running. If something goes wrong with the NameNode and it goes down, then the entire file system goes offline and HDFS cluster is unavailable until restart manually or run on a separate machine and it would take sometime. That’s what we called the NameNode is a Single Point of Failure (SPOF) for the HDFS cluster and would result in periods of cluster downtime.
Solution-4: The HDFS High Availability feature addresses the above problems by providing the option of running two NameNodes in the same cluster, in an Active/Passive configuration. These are referred to as the Active NameNode and the Standby NameNode. Unlike the Secondary NameNode, the Standby NameNode is hot standby, allowing a fast failover to a new NameNode in the case that a machine crashes, or a graceful administrator-initiated failover for the purpose of planned maintenance. In a typical HA cluster, two separate machines are configured as NameNodes. At any point in time, one of the NameNodes is in an Active state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state (through checkpointing process) to provide a fast failover if necessary. You can get detail discussion on HDFS HA feature in my previous post “Hadoop HDFS High Availability“.
Now our NameNode server is Highly Available. It’s time to think our NameNode server’s scalability (horizontal).
Issue-5: Now there is only one NameNode (i.e Active NameNode) in a cluster, which maintains a single namespace for the entire cluster. Regarding that Hadoop cluster is becoming larger and larger one enterprise platform and stores the entire file system metadata is in NameNode memory (RAM), when there are more than 4000 data nodes with many files, the NameNode memory will reach its limit and it becomes the limiting factor for cluster scaling.
Solution-5: To overcome this problem, Hadoop introduces HDFS Federation(a federation of NameNades that statically partition the filesystem namespace), which allows a cluster to scale by adding more NameNodes horizontally, each of which manages a portion of the filesystem namespace (see figure). Namenodes are federated, that is, all these NameNodes work independently and don’t require any co-ordination with each other. You can get detail discussion on HDFS Federation in my post “Hadoop HDFS Federation“.
